官方网站登录入口")
官方网站登录入口")

万博manbext体育官网app娱乐除了数据视角下的模子压缩-万博manbext体育官网(中国)官方网站登录入口

上海交大、27 岁、最年青博导万博manbext体育官网app娱乐,留给张林峰的标签未几了(Doge)。

最新激励宥恕的,是他实简直在的一个论文效果——
他们提议了一种新的数据集蒸馏才略,截至取得了CVPR 2025 满分。
通过引入一个提拔的神经会聚,只需一块 6 年前的 2080Ti,就能作念大模子数据蒸馏。与前 SOTA 比较,新才略的显存占用惟有 1/300,况兼速率进步了 20 倍。
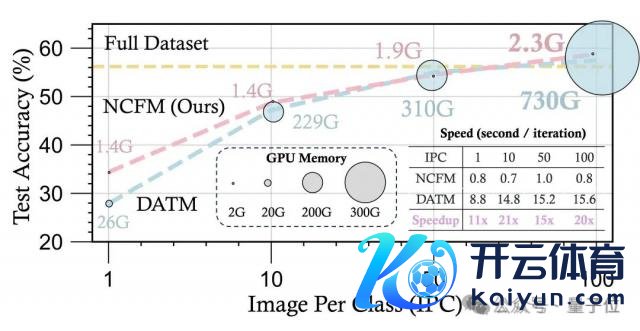
不外关于这一截至,张林峰暗示有点不测。但能确定的是「数据蒸馏」这一范式会成为接下来模子压缩的趋势之一。
履行上模子压缩这个畛域其实并不新。算作机器学习中的一个分支,它旨在减少模子的复杂度、存储空间或计算资源需求,同期尽可能保执其性能。像全球熟知的剪枝、量化、蒸馏都是模子压缩的传统才略。
跟着大模子波浪深刻,「纵欲出古迹」范式启动受到质疑,由 DeepSeek 为代表带起的「高效低资本」的趋势,让模子压缩再度受到业内宥恕,回到舞台中央。
而永恒在这个畛域深耕的张林峰,关于模子压缩若何走?如何走?他有着我方的主意。量子位与张林峰伸开聊了聊。
大模子压缩:加快底座模子
从张林峰团队最近几个商榷启动看起。
当先说谈说谈被 CVPR 评为满分论文的 NFCM。它的中枢是引入了一个新的散布各异度量 NCFD,并将数据集蒸馏问题滚动为一个 minmax 优化问题。
通过瓜代优化合成数据以最小化 NCFD,以及优化采样会聚以最大化 NCFD,NCFM 在进步合成数据质地的同期,不停增强散布各异度量的敏锐性和灵验性。
在多个基准数据集上,NCFM 都取得了权贵的性能进步,并展现出可彭胀性。在 CIFAR 数据集上,NCFM 只需 2GB 傍边的 GPU 内存就能达成无损的数据集蒸馏,用 2080Ti 即可达成。况兼,NCFM 在连气儿学习、神经架构搜索等卑鄙任务上也展现了优异的性能。
这其实代表着张林峰团队所作念的一个方针:通过数据的角度去加快模子。
现时 AI 模子需要基于海量数据进行锤真金不怕火,这权贵加多了大型模子的锤真金不怕火资本。咱们商榷如何更高效地诳骗数据,更科学地清洗和合成数据,并诳骗合成数据进一步增强生成模子,从而达成数据高效的东谈主工智能。
具体是什么趣味?
张林峰解释谈,一个模子的计算,轮廓出来便是参数 w 和数据 x 去算矩阵乘法。按照之前的念念路,便是对参数 w 进行压缩,但一朝参数改变就需要再行锤真金不怕火,幸免它赔本那么多信息。既然这个念念路当今达成不了,那就尝试来压缩数据 x。
当锤真金不怕火数据集都是精挑细选的高质地数据,在通过这些高质地数据去进行合成,锤真金不怕火资本就会不错缩小,同期也不会出现过拟合的情况。
现阶段,他们有个方针便是通过数据压缩来提高锤真金不怕火的着力,他们里面有个筹算,那便是锤真金不怕火从简的资本 / 挑选数据资本是>1 的,这也就证实这一时间念念路是可行且有价值的。但咫尺还只可在一些阶段和场景中可行。
最近,他们发表在 ACL2025 的一篇著作照旧在大模子微调锤真金不怕火阶段达成了这个方针,通过落魄文体习大幅度提高了后锤真金不怕火数据筛选的速率和精度(http://arxiv.org/abs/2505.12212)。

畴昔有可能的话,参数压缩和数据压缩其实不错自然联结起来。
除了数据视角下的模子压缩,他们另一个方针在于:模子锤真金不怕火阶段删掉 token,让锤真金不怕火资本变低。或者在推理阶段删掉 token,让模子推理速率变快。
比如,他们发当今最近火热的扩散谈话模子上,不错通过删除 token 达成最高 9 倍的加快而险些莫得性能赔本(https://github.com/maomaocun/dLLM-cache)。在多模态大模子上,不错删除图像视频中 80% 以致 90% 的 token,仍然能保执很高的精度……

当今他们照旧将这一探索从谈话模子蔓延到了视觉生成板块。
他们提议了一个叫作念Toca,token 级别的特征缓存(Token-wise Caching)的才略。
这是初次从 token 级别达成了扩散模子在图像和视频生成上,无需锤真金不怕火就达成两倍以上的加快。这解决的是 Diffusion Transformer 计算资本高的清贫。

之前的缓存才略忽略了不同的 token 对特征缓存施展出不同的敏锐性,而对某些 token 的特征缓存可能导致生成质地举座上高达 10 倍的阻挡。
他们的才略允许自适合地遴荐最相宜进行缓存的 token,并进一步为不同类型和深度的神经会聚层应用不同的缓存比率。
这个念念路还不错针对不同任务作念有益优化,比如在图像裁剪任务上,惟有被裁剪的区域是需要宥恕和计算的,莫得被裁剪区域上的计算不错尽量的减少。基于这个念念路,他们把 token 级别的特征缓存又用到了图像裁剪任务上(https://eff-edit.github.io/)。
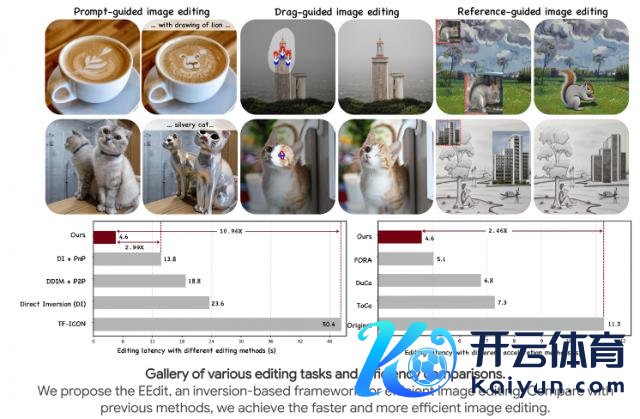
而最新的TaylorSeer恰是这一念念路的无间。他们但愿 TaylorSeer 能够将特征缓存的范式从复用转机到瞻望,像预言家通常预言下一步的特征是什么。

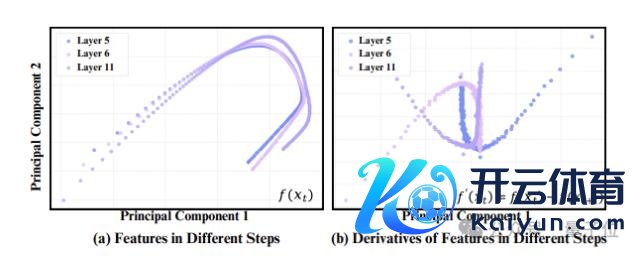
他们发现扩散模子在特征空间上随时刻步的变化瑕瑜常褂讪而连气儿的,这证实不错径直基于径直时刻步的特征用泰勒伸开瞻望出下一步的特征,而不需要的确的去计算。
从念念路上讲,传统的扩散模子缓存才略是缓存上一步的特征,不才一步上进行"径直复用";咱们的才略是缓存上一步的特征,对下一步特征进行"瞻望",其精度赫然会高出径直复用的面孔。
最终在 DiT、FLUX、Hunyuan Video、WAN、FramePacker、SDXL 等模子上都达成了接近 5 倍的加快效果,此外音频生成、图像超分辨率、图像裁剪、以致是具身智能等任务上也进行超过胜的尝试。
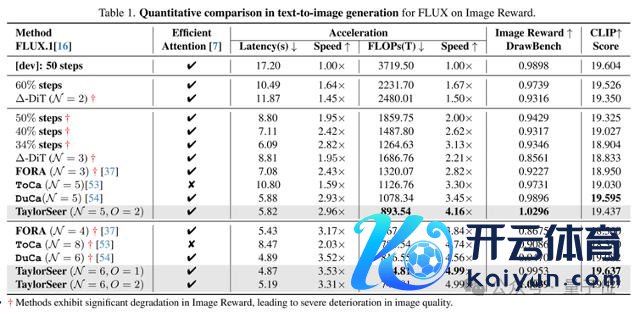
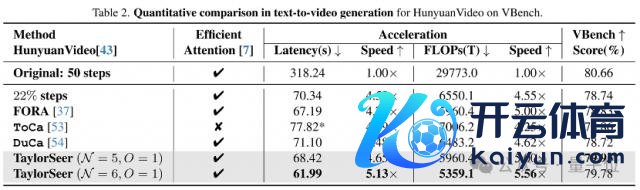
加快后的模子在使用八卡 GPU 推理时,照旧不错让 HunyuanVideo 对视频的生成速率靠拢于播放速率。
这一系列商榷效果照旧开源,况兼渐渐在多样模子中部署。

https://github.com/Shenyi-Z/TaylorSeer
张林峰显现,他们当今的一个历久方针所以极低地资本即插即用地加快随便的开源视频生成模子,最终让视频生成模子的生成速率高出视频的播放速率。
这就意味着,咱们在播放一个视频的时候,它在后台同期生成一个视频,感知层面上讲险些是及时生成视频的。
从这几个商榷中,其实能看到张林峰团队的几个方针,同期也代表着模子压缩的几个趋势,比如数据视角下的模子压缩;从谈话模子蔓延到多模态生成模子的加快。
但总归目的惟有一个:缩小大模子的部署资本,使其更好地应用于现实宇宙。
从本科大三就直至当今助理栽植这孤单份,张林峰永恒在探索这一方针。他坦言从时间到自身心理都发生了许多变化。
从「模子压缩」到「大模子压缩」
最早是在 2018 年底,张林峰彼时莫得商量到那么多,仅仅认为方针好玩,再者工业界也比较宥恕这一方针。
当今追忆,他暗示:
固然作念过许多调研,但也弗成能预意想大模子期间的到来。
其时他大四一篇自蒸馏的著作,奠定了他之后方针的基础,也给通盘学界和工业界一个念念路,时于当天被引数高出了 1100+,并被同方针大神 MIT 副栽植韩松(2023 年斯隆商榷奖得主、深鉴科技麇集首创东谈主),写进了《TinyML and Efficient Deep Learning Computing》这门课程的 Lecture 9《Knowledge Distillation》。
这篇著作是《Be your own teacher: lmprove the performance of convolutional neuranetworks via self distillation》(《通过自蒸馏提高卷积神经会聚的性能》),发表于 ICCV2019。
它提议了一种自蒸馏通用锤真金不怕火框架——使用模子的深层来蒸馏浅层。
该才略将方针 CNN 按深度和原始结构辞别为几个浅层部分,在每个浅层部分后成立一个由瓶颈层和全连结层构成的分类器(仅在锤真金不怕火时使用,推理时可移除)。
锤真金不怕火时,通盘浅层部分过火分类器算作学生模子,通过蒸馏从最深层部分(视为教师模子)获取学问。在权贵提高 CNN 性能的同期,锤真金不怕火时刻也更短。
这篇论文证实了学问蒸馏中的教师模子并非必需,而是我方同期饰演老到和学生,鼓动了无教师学问蒸馏畛域的发展。
如今再来看学问蒸馏,他认为学问蒸馏的发展不错分为三个阶段。
第一个阶段是强的大模子来当老到,来锤真金不怕火弱的小模子(学生模子)。
第二个阶段便是自蒸馏,稀奇于是老到和学生其实是并吞种模子,材干是差未几的,我方教我方然后让我方变得更为重大,这其简直咫尺垂直畛域中智能体应用中很常见。
第三个阶段,现阶段通盘科研社区比较宥恕的一个畛域,便是从弱到强蒸馏——让一个小的弱模子当老到,然后让一个强的模子当学生,通过弱的模子去进步强的模子。这一方针十分具有前瞻性,因为若是一朝能达成,这就证实不错达成 AI 的进化,模子不错越来越强。

不外这样的想法,若是放在其时并不会受到太多宥恕。以致模子压缩这个商榷方针一度险遭停滞:是不是要转行了?!
2020 年时期,模子启动从「越来越小」的方针发展,从一启动的几十兆、几百兆到其后几兆、以致压缩到几 KB 模子。模子压缩似乎莫得什么余步,张林峰感到「没什么能作念的」。
截至转机是在大模子出现,全球惊呼:哇噻,模子还能这样大哈?

张林峰显现,许多新手或者不懂 AI 的东谈主问他,你看当今都讲大模子,截至你作念模子压缩,是不是与期间以火去蛾中?
他暗示,履行上模子越大,其实就越需要压缩。
咱们当今每天都盼着,哪天再出来一个 10 万亿的,最好再出来一个百万亿的模子,那就更欣忭了。
固然都是偏应用技俩,与昔时作念模子压缩比较,张林峰一个赫然的感知便是商榷越来越fancy 了。
本科毕业时他用自蒸馏给图像分类模子作念加快,截至作念出来的 Demo 给身边东谈主看,截至他们都暗示:so what?霎时有刹那间他认为这个技俩好像莫得什么趣味——因为仅仅给图像作念了个分类。
而当今时间带来的改变是肉眼可见、即时可感知的。比如视频生成提速 5 倍,蓝本需要 50 秒生成的截至,当今只需 10 秒就不错处分。
这些具象化的产出自然具备趣味趣味属性——不论是生成图像、逻辑推理照旧视觉贯通,所带来的建树感也就稀奇直不雅。
不外还仅仅表象的变化,时间层面的区别照旧不小。
主要体当今这几个方面:一个是方针窜改,另一个则是时间复杂性的各异。
传统模子压缩以结构优化为中枢,找到最好的架构,允许殉难照旧学到的学问(如减少卷积层数、通谈数),通事后续再行锤真金不怕火即可复原性能。像剪枝、量化、蒸馏便是比较经典的模子压缩的才略。
而以千亿参数的大模子来讲,则需要需均衡结构着力与学问保留,压缩历程必须最小化学问赔本。因为若是要再即将大模子跑起来是算力、数据、工程造就等多重考验。现实情况是每个作念模子压缩的东谈主并不具备的确让模子在压缩中丢掉的学问再学会来的这个材干。
相悖当今数据视角下的模子压缩里许多责任,鼓胀不需要锤真金不怕火,通盘资本就会低许多:
不祥便是租个 GPU 的用度就不错处分。
从履行上讲,这种不需要锤真金不怕火的才略,是在诳骗模子自己具有的冗余性,然后将这种冗余性减少。
不外当高度致密的模子出来,是不是不需要模子压缩了?!
靠近这一问题时,张林峰暗示:如实存在。
不外当今这个阶段,全球照旧在野着大模子这一方针走,稀奇像视频生成这个方针。总的来说,谈阻且长。
但愿不要以年龄来界说
像这样年岁轻轻就当上助理栽植启动展露头角,张林峰仅仅一个代表。仅在他们学院就有许多年青老到,以致比他还要小。
张林峰谈到,年青老到一上来确定元气心灵会多极少,关于学生的设备也会更多极少。许多宠爱科研的同学,初学可能需要有个东谈主妙手把手去带,那年青老到就稀奇相宜这个位置,全球共同从零到一地去产出效果。
若是抛开年龄标签,张林峰坦言我方跟大多量作念科研的东谈主通常,但愿别东谈主用他们作念过的科研效果来记取他们。
比如作念学问蒸馏的、作念模子压缩的、作念数据视角下让模子变得更快的。
我就但愿全球就记取我的是我作念出过什么责任,而不仅仅我的名字。
张林峰团队也跟他通常,一通盘主打年青化作风,一拨是他我方的学生;另一拨便是商榷助理,大部分是本科生。
关于进来的学生,张林峰暗示只需原意两点条款。
一个是 Motivation,的确可爱作念科研的,认为这个方针很好玩。另一个则是有基础的编程材干。除此以外,莫得其他任何条款。也就意味着许多非计算机专科学生也有契机进组作念商榷,而且当今也不啻他们组,其实这种跨专科参与的风景稀奇赫然。
终末,还问了问张林峰,看到现时这样多大模子创业团队,是否有兴味创业呢?
他念念考了俄顷暗示:看有莫得这样更好的效果滚动契机,毕竟作念科研照旧很烧钱的。
可是归正若是莫得找到稀奇好的点的话,我也不想便是为了创业去创业,可是我会一直宥恕的。
好哦,莫得否定。
— 完 —
� � 量子位 AI 主题筹备正在搜集会!宽饶参与专题365 行 AI 落地决策,一千零一个 AI 应用,或与咱们共享你在寻找的 AI 居品,或发现的AI 新动向。
� � 也宽饶你加入量子位逐日 AI 换取群,一皆来畅聊 AI 吧~
一键宥恕 � � 点亮星标
科技前沿进展逐日见
一键三连「点赞」「转发」「防范心」
宽饶在批驳区留住你的想法!万博manbext体育官网app娱乐
